二分木の図
二分木とは木構造の1つです。
データが格納される場所をノード(節)と言い、データをつないでいる線をブランチ(枝)と言います。
その中でも1つのノードに0から2個のノードがつながっている構造を二分木構造と言います。
あるノードを基準にして、左にあるノードは基準の値よりも小さく、右にあるノードは基準よりも大きい値が入っています。
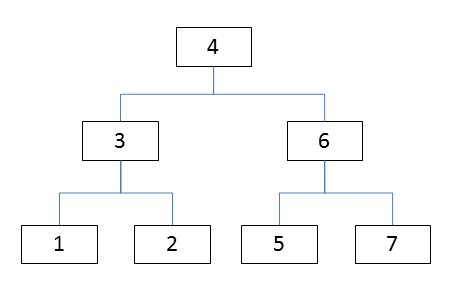
図にすると↓のようになります。
二分木の図
setはこの二分木構造を提供するコンテナです。
二分木の特徴を書きます。
・添え字によるアクセスは不可 (イテレータによるアクセスは可) ・insert関数によってデータを追加する ・値(キー)による大小関係を保持しているので、 イテレータで全データにアクセスした場合、 ソートされた状態になっている。 |
実際にサンプルを作ってみましょう。
乱数を10個生成し、setに格納してデータを確認するプログラムを作ります。
<sample program cpp021-01>
#include <iostream>
#include <set>
#include <cstdlib>
#include <ctime>
int main()
{
srand((unsigned int)time(NULL));
std::set<int> setData;
for (int i = 0; i < 10; i++) {
setData.insert(rand() % 100);
}
std::set<int>::iterator it;
for (it = setData.begin(); it != setData.end(); it++) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
|
<実行結果>
10 17 26 44 47 50 62 66 73 77 続行するには何かキーを押してください・・・
格納したデータが昇順に並んでいるのが分かります。
この構造の利点は「データの検索が早い」という点でしょう。
なぜそう言えるのか、もう一度図を見てみます。
二分木の図
この状態で、5があるかどうか探索を始めます。
最初に比較するデータは一番上にある4です。
5の方が大きいので、右のノードを調べます。
次に比較するデータは6です。
5の方が小さいので、左のノードを調べます。
ここで見つかりました。
比較回数は3回です。
C言語編でやった「二分探索」と同じ考え方ですね。
1つ注意点がありますので、何度か実行してデータの数をよく見てください。
たまに9個しか表示されない事がありませんか?
上のプログラムの乱数の幅を狭めて確かめてみましょう。
<sample program cpp021-02>
#include <iostream>
#include <set>
#include <cstdlib>
#include <ctime>
int main()
{
srand((unsigned int)time(NULL));
std::set<int> setData;
for (int i = 0; i < 10; i++) {
setData.insert(rand() % 10);
}
std::set<int>::iterator it;
for (it = setData.begin(); it != setData.end(); it++) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
|
<実行結果>
0 1 2 5 6 7 9 続行するには何かキーを押してください・・・
10個のデータを格納したはずですが、7個しか表示されていません・・・
実はsetは重複したデータを格納できないのです。
短いプログラムで試してみましょう。
<sample program cpp021-03>
#include <iostream>
#include <set>
int main()
{
std::set<int> setData;
setData.insert(5);
setData.insert(5);
std::cout << setData.size() << std::endl;
return 0;
}
|
<実行結果>
1 続行するには何かキーを押してください・・・
2つ値を格納したはずですが、データの個数は1つとなっています。
格納できたのか、格納できなかったのか調べる方法があります。
insert関数は戻り値を返していますので、それを調べます。
ただ、戻り値は特殊な型でpair(ペア)と呼ばれる形で戻されます。
先にpairについて説明しましょう。
pairというのは2つのデータをセットにして格納できる仕組みです。
2つのデータ型はテンプレートで指定し、1つ目のデータはfirst、2つ目のデータはsecondと言う名前でアクセス出来ます。
例を書きます。
<sample program cpp021-04>
#include <iostream>
#include <set>
int main()
{
std::pair<int, double> data;
data.first = 13;
data.second = 25.3;
std::cout << "first = " << data.first << std::endl;
std::cout << "second = " << data.second << std::endl;
return 0;
}
|
<実行結果>
13 25.3 続行するには何かキーを押してください・・・
では、insert関数の戻り値を調べましょう。
insert関数の戻り値は「イテレータとbool」のペアで返されます。
そこで、↓のようなペアを作ります。
std::pair<std::set<int>::iterator, bool> |
これを型として実体を作り、戻り値を受け取ります。
secondがtrueの場合格納OKで、falseの場合格納出来なかったと言う事になります。
<sample program cpp021-05>
#include <iostream>
#include <set>
int main()
{
std::set<int> setData;
std::pair<std::set<int>::iterator, bool> result;
result = setData.insert(5);
if (result.second) {
std::cout << "OK" << std::endl;
}
else {
std::cout << "NG" << std::endl;
}
result = setData.insert(5);
if (result.second) {
std::cout << "OK" << std::endl;
}
else {
std::cout << "NG" << std::endl;
}
return 0;
}
|
<実行結果>
OK NG 続行するには何かキーを押してください・・・
1回目は「"OK"」と表示されましたが、2回目に同じ値を入れると「"NG"」と表示されました。
もう1つfind関数を使って、格納する前に同じデータがあるかどうか調べる方法もあります。
find関数は探したいデータを引数で渡すと、データのある場所(イテレータ)を返します。
データが無かった場合、最後のデータの次のイテレータ「.end()」を返します。
とりあえず、サンプルを作ってみましょう。
<sample program cpp021-05>
#include <iostream>
#include <set>
int main()
{
std::set<int> setData;
setData.insert(5);
if (setData.find(5) != setData.end()) {
std::cout << "Find" << std::endl;
}
else {
std::cout << "Not Found" << std::endl;
setData.insert(5);
}
return 0;
}
|
<実行結果>
Find 続行するには何かキーを押してください・・・
find関数の戻り値と「setData.end()」を比較する事であったかどうか分かります。
無かった場合だけ、値を格納するようにすれば良いのです。
最後に、setは重複データを格納出来ませんが、multisetであれば重複データも格納出来ます。
試したい方はご自身でサンプルを作ってみてください。